Tutoriel sur GraphQL

1. Objectif
Nous allons ici apprendre les bases de l’utilisation en Python (avec
les bibliothèques Flask et Ariadne) de GraphQL. Nous tentons ici de mettre en avant les
avantages de GraphQL au travers d’une utilisation concrète sur le service
Movie précédemment codé en REST.
|
Important
|
Tout comme pour Flask merci de vous référer à la page d’installation avant de continuer.
|
Téléchargez le contenu du repository git suivant : https://github.com/IMTA-FIL/UE-AD-A1-MIXTE
Le contenu de ce repository sera votre espace de travail pour ce tutoriel et votre TP sur les API mixtes. Il contient un répertoire par service à implémenter dans le TP, dont un répertoire pour le service Movie qui nous intéresse ici. Chaque répertoire de service contient les données json qui lui sont associées.
Le repository, comme indiqué dans le guide d’installation, contient également un fichier requirements.txt racine utile pour installer les dépendances nécessaires (à savoir ici les bibliothèques Flask requests ariadne grpcio grpcio-tools). Il contient enfin les fichiers nécessaires à la construction de l’environnement Docker, à savoir un fichier docker-compose.yaml et dans chaque répertoire un fichier requirements.txt et un Dockerfile.
2. Ré-écriture d’un point d’entrée GET de Movie en GraphQL
Nous allons dans un premier temps coder le service Movie en GraphQL avec
uniquement la point d’entrée relatif à un film à partir de son ID.
2.1. Un premier schéma
Nous allons éditer le fichier schéma GraphQL appelé movie.graphql. Ce fichier contient l’ensemble des requêtes
qu’il est possible de faire sur le service spécifié, ainsi que les types associés.
Voici le contenu de ce fichier. Nous avons ici la déclaration d’une seule
requête nommée movie_with_id qui prend en argument un String obligatoire
(!) que nous nommons _id, et qui retourne un élément de type Movie. Ce
type est décrit juste après comme un objet constitué des fields suivants : un
ID, un titre, un directeur et une note.
type Query {
movie_with_id(_id: String!): Movie
}
type Movie {
id: String!
title: String!
director: String!
rating: Float!
}2.2. Un premier "Resolver"
Un "resolver" est une fonction qui permet de résoudre le type d’un field
lorsque celui-ci n’est pas Scalar (types de base). Ils permettent donc de résoudre les
requêtes en parcourant les fields du schéma GraphQL. Editons le fichier
spécifique qui contiendra l’ensemble des fonctions de résolution resolvers.py.
Nous allons y définir une unique fonction de résolution pour le moment que
nous allons appeler par simplicité comme la requête du schéma
movie_with_id, mais nous aurions pu l’appeler autrement.
La signature d’un "resolver" est particulière, il s’agit d’une fonction
appelée par GraphQL lors de la résolution d’un field. Le premier
argument de la fonction correspond à l’objet parent du field. Cela
parait pour le moment un peu flou, mais s’éclairera par la suite. Ici il n’y a
pas de field parent, car ce resolver est appelé directement depuis la requête
(objet racine _). Le deuxième argument correspond aux informations de la
requête (que nous n’utiliserons pas dans ce tutoriel) puis viennent ensuite les arguments correspondant aux entrées de la
requête comme déclarées dans le schéma : ici donc _id.
Dans ce resolver nous allons simplement charger en lecture le fichier movie
.json puis y chercher l’entrée correspondante à _id. Une fois trouvé nous
retournons le film associé.
import json
def movie_with_id(_,info,_id):
with open('{}/data/movies.json'.format("."), "r") as file:
movies = json.load(file)
for movie in movies['movies']:
if movie['id'] == _id:
return movieAriadne (GraphQL) s’occupe de faire la correspondance entre le format json du film
retourné et les attributs du type Movie déclaré dans le schéma, à condition
que les clés correspondent aux "fields" du type déclaré. Ici nous avons bien
correspondance :
{
"title": "The Good Dinosaur",
"rating": 7.4,
"director": "Peter Sohn",
"id": "720d006c-3a57-4b6a-b18f-9b713b073f3c"
}type Movie {
id: String!
title: String!
director: String!
rating: Float!
}2.3. Création des points d’entrée, types, bindings et schémas
Nous devons maintenant faire en sorte que GraphQL intègre le schéma défini
et associe ses fields objets (non scalar) aux resolvers associés.
GraphQL (dans sa version Ariadne) s’intègre très bien à
Flask. Nous allons créer un fichier Python Flask movie.py correspondant à
notre service.
Voici le fichier de base de notre service avec un point d’entrée racine. Nous
voyons déjà que nous y importons des objets de Ariadne que nous
détaillerons ensuite. Nous importons aussi le resolver que nous nommons r.
from ariadne import graphql_sync, make_executable_schema, load_schema_from_path, ObjectType, QueryType, MutationType
from flask import Flask, request, jsonify
import resolvers as r
PORT = 3001
HOST = '0.0.0.0'
app = Flask(__name__)
# todo create elements for Ariadne
# root message
@app.route("/", methods=['GET'])
def home():
return make_response("<h1 style='color:blue'>Welcome to the Movie service!</h1>",200)
# graphql entry points
@app.route('/graphql', methods=['POST'])
def graphql_server():
# todo to complete
if __name__ == "__main__":
print("Server running in port %s"%(PORT))
app.run(host=HOST, port=PORT)GraphQL utilise simplement un point d’entrée pour s’intégrer à Flask sur
une méthode POST. Cette requête HTTP/1.1 de type POST permet d’envoyer ses requêtes GraphQL.
@app.route('/graphql', methods=['POST'])
def graphql_server():
# A COMPLETERPour compléter la requête de type POST nous allons devoir créer un certain
nombre d’éléments juste après le commentaire # todo create elements for
Ariadne.
Tout d’abord, il nous faut charger les types déclarés dans le schéma GraphQL
type_defs = load_schema_from_path('movie.graphql')Nous devons ensuite créer les objets associés au schéma. Ici nous avons pour
le moment deux types d’objets, Query et Movie.
query = QueryType()
movie = ObjectType('Movie')Nous devons ensuite associer le "resolver" que nous avons codé à la requête associée dans le schéma.
query.set_field('movie_with_id', r.movie_with_id)Enfin, nous créons un schéma dit exécutable avec les éléments précédents.
schema = make_executable_schema(type_defs, movie, query)Voici maintenant le contenu du point d’entrée utilisant la méthode POST.
Nou y utilisons la fonction graphql_sync importée au départ et qui permet à
partir du body ou contenu de la requête POST, c’est-à-dire de la requête
GraphQL (ici placée dans data), de résoudre la requête en utilisant le
schéma créé précédemment. Cette fonction retourne le résultat de la requête et
un code de succès. Ce code la restera inchangé ensuite et vaut pour toute API GraphQL.
@app.route('/graphql', methods=['POST'])
def graphql_server():
data = request.get_json()
success, result = graphql_sync(
schema,
data,
context_value=None,
debug=app.debug
)
status_code = 200 if success else 400
return jsonify(result), status_code2.4. Tests
Nous allons maintenant tester notre service et notre unique requête possible
movie_with_id. Commençons par lancer notre service :
pymon movie.pyou (avec la version de Python récente)
python movie.pyVous devriez observer la sortie habituelle Flask:
Server running in port 5000
* Serving Flask app "movie" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://localhost:5000/ (Press CTRL+C to quit)Allons maintenant tester notre API sur Postman (ou équivalent). Créons une nouvelle collection de requêtes pour ce tutoriel. Il suffit de créer des requêtes HTTP comme pour REST mais certains outils peuvent proposer une intégration spécifique à GraphQL. Nous devons créer une requête de type POST avec un body de type GraphQL contenant la requête suivante :
query{
movie_with_id(_id:"96798c08-d19b-4986-a05d-7da856efb697") {
id
title
rating
director
}
}Nous faisons donc une requête query movie_with_id en donnant l’id
96798c08-d19b-4986-a05d-7da856efb697, et nous demandons l’ensemble des
données sur le film, à savoir l’id, le titre, la note et le directeur. Vous
devez observer la réponse suivante en json :
{
"data": {
"movie_with_id": {
"director": "Jonathan Levine",
"id": "96798c08-d19b-4986-a05d-7da856efb697",
"rating": 7.4,
"title": "The Night Before"
}
}
}A noter qu’avec Postman on peut créer une API de type graphQL et importer le schéma movie.graphql. Ainsi Postman nous propose directement les rquêtes possible et les fields que l’on peut récupérer.
C’est ici que nous allons voir la puissance de GraphQL puisque nous allons
pouvoir faire une requête contenant uniquement les données dont nous avons
besoin. Par exemple je ne peux avoir besoin que du titre et de la note du film :
query{
movie_with_id(_id:"96798c08-d19b-4986-a05d-7da856efb697") {
title
rating
}
}{
"data": {
"movie_with_id": {
"rating": 7.4,
"title": "The Night Before"
}
}
}GraphQL permet donc de s’adapter à chaque client et de n’envoyer sur le
réseau que les données d’intérêt sans pour autant multiplier le nombre de
points d’entrée pour le service.
3. Ré-écriture d’un point d’entrée POST de Movie en GraphQL
Mais alors s’il y a un seul point d’entrée utilisant la méthode POST, comment spécifier une modification ou une création de données au
service comme nous l’aurions fait en REST avec les méthodes GET, POST`, PUT
et DELETE ?
3.1. Objets "mutation"
Avec un resolver on écrit le code que l’on souhaite exécuter pour résoudre la
valeur d’un field. Donc le resolver d’une requête pourrait venir modifier ou
supprimer des données. Toutefois, il est préférable que l’utilisateur sache
qu’il va modifier des données et GraphQL offre donc le type Mutation.
Voici notre nouveau schéma :
type Query {
movie_with_id(_id: String!): Movie
}
type Mutation {
update_movie_rate(_id: String!, _rate: Float!): Movie
}
type Movie {
id: String!
title: String!
director: String!
rating: Float!
}Nous avons ajouté une mutation update_movie_rate qui prend en entrée un
_id et une nouvelle note _rate à affecter au film correspondant à l’id. La
mutation nous retourne le film avec la note mise à jour.
3.2. Resolver d’une mutation
Tout comme pour une requête, nous devons écrire un "resolver" pour une mutation.
def update_movie_rate(_,info,_id,_rate):
newmovies = {}
newmovie = {}
with open('{}/data/movies.json'.format("."), "r") as rfile:
movies = json.load(rfile)
for movie in movies['movies']:
if movie['id'] == _id:
movie['rating'] = _rate
newmovie = movie
newmovies = movies
with open('{}/data/movies.json'.format("."), "w") as wfile:
json.dump(newmovies, wfile)
return newmovieComme pour movie_with_id, le premier argument du resolver correspond à
l’objet parent dans la mutation. Ici il n’y a pas d’objet parent car ce
resolver est appelé directement à l’appel de la mutation (type racine _). Le
deuxième argument correspond aux informations de la requête puis viennent
ensuite les arguments correspondant aux entrées de la mutation donc _id et
_rate.
Dans ce resolver, nous commençons par trouver le film correspondant à _id,
nous mettons alors à jour sa note avec _rate. Nous récupérons les données
correspondantes à ce film dans newmovie ainsi que plus globalement le
nouveau json modifié dans newmovies. Nous écrivons maintenant le nouveau
fichier movies.json et nous retournons en réponse de la requête le film
newmovie.
3.3. Création du type, binding et schéma associé
Nous devons maintenant associer le resolver à la mutation déclarée dans le schéma. Nous faisons donc les modifications suivantes :
mutation = MutationType()
mutation.set_field('update_movie_rate', r.update_movie_rate)
schema = make_executable_schema(type_defs, movie, query, mutation)3.4. Tests
Une mutation marche donc en tout points comme une requête, mais permet à l’utilisateur de savoir qu’il va modifier des informations.
Relançons le service Movie et allons dans le point d’entrée /graphql. Nous
allons maintenant faire la requête suivante :
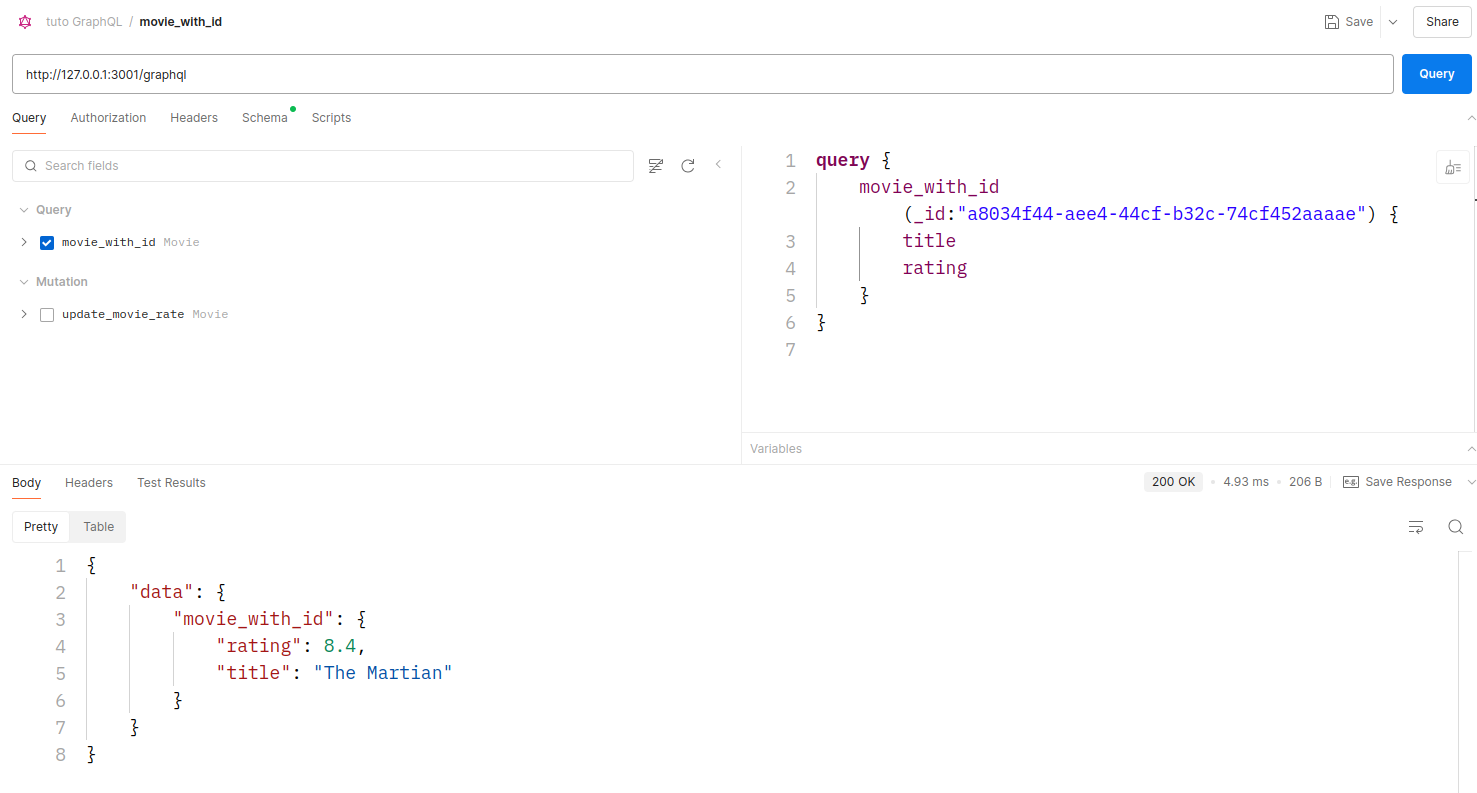
mutation{
update_movie_rate(_id:"a8034f44-aee4-44cf-b32c-74cf452aaaae",_rate:8.4) {
title
rating
}
}Ici nous mettons à jour la note du film "The Martian" à 8.4 au lieu de 8
.2, et nous demandons à GraphQL de nous retourner uniquement le titre et
la nouvelle note du film. Nous obtenons la réponse suivante et le fichier
movie.json a été modifié.
{
"data": {
"update_movie_rate": {
"rating": 8.4,
"title": "The Martian"
}
}
}4. Evolution du service Movie
Nous allons faire évoluer le service Movie afin de voir un autre intérêt de
GraphQL en plus de pouvoir demander la forme de réponse de son choix et
d’éviter de transporter de l’information inutile sur le réseau.
4.1. Les acteurs actors.json
Pour cela nous allons ajouter un fichier data/actors.json déjà en place sur le repo. Un exemple d’acteur dans ce fichier :
{
"id": "actor4",
"firstname": "George",
"lastname": "Clooney",
"birthyear": 1961,
"films": ["a8034f44-aee4-44cf-b32c-74cf452aaaae"]
}Vous pouvez voir que la définition d’un acteur contient une liste de films dans lesquels l’acteur a joué.
4.2. Reflexion sur une nouvelle fonctionnalité de notre service, comparaison REST et GraphQL
À partir de ce nouveau fichier, nous allons pouvoir retourner en plus des
informations sur le film des informations sur les acteurs qui ont joué dedans
. Pour cela une jointure est nécessaire sur l’ID des films entre les
données contenues dans movie.json et actors.json.
En REST deux possibilités s’offrent à nous :
-
Modifier le point d’entrée existant
/movie/<movieid>de façon à ce que la réponse contienne également les informations sur les acteurs du film, mais l’inconvénient est que si des clients étaient satisfaits de l’information sur les films uniquement, plus de données leur seront transmises. -
Créer un nouveau point d’entrée spécifique par exemple
/movieactors/<movieid>mais alors l’utilisateur qui a besoin de toute les informations a besoin d’utiliser 2 points d’entrée/movie/<movieid>et/movieactors/<movieid>
La puissance de GraphQL, et en particulier l’aspect hiérarchique des
"resolvers", va nous permettre de gérer ces nouvelles informations en fonction
du besoin des utilisateurs sans modifier l’unique point d’entrée.
4.3. Nouveau schéma
Nous allons modifier le type Movie du schéma comme ceci :
type Movie {
id: String!
title: String!
director: String!
rating: Float!
actors: [Actor]
}Nous y avons ajouté un field actors qui correspond à une liste d’acteurs de
type Actor défini comme ceci (en suivant les informations du fichier
actors.json) avec un identifiant, un prénom, un nom, une année de naissance
et une liste d’id de films :
type Actor {
id: String!
firstname: String!
lastname: String!
birthyear: Int!
films: [String!]
}Ici donc la requête movie_with_id qui retourne un type Movie doit
également retourner une liste d’acteurs. Voyons ce qui se passe si nous
tentons de lancer notre service et de faire la requête suivante :
query{
movie_with_id(_id:"96798c08-d19b-4986-a05d-7da856efb697") {
title
rating
actors{
firstname
lastname
birthyear
}
}
}La requête contient maintenant la description de la réponse attendue pour la liste des acteurs qui ont joué dans le film. Mais nous obtenons la réponse suivante :
{
"errors": [
{
"locations": [
{
"column": 5,
"line": 5
}
],
"message": "Cannot query field 'actors' on type 'Movie'."
}
]
}La liste des acteurs n’existe pas dans le json de movie et nous n’avons codé nulle part
comment résoudre ce field Object (faire la jointure avec actors.json) !
4.4. Resolver imbriqués
Nous allons donc lui offrir un resolver mais qui cette fois ne sera
pas rattaché à la requête principale directement (premier argument _) mais à
l’objet parent movie. Voici le code de notre resolver :
def resolve_actors_in_movie(movie, info):
with open('{}/data/actors.json'.format("."), "r") as file:
actors = json.load(file)
result = [actor for actor in actors['actors'] if movie['id'] in actor['films']]
return resultLe contexte dans lequel se trouve notre resolver est de connaître l’objet
movie duquel est apparu l’appel à ce resolver. Il a donc accès aux données
associées à ce film movie qui est un dictionnaire correspondant aux données
json. Notre resolver va ouvrir le fichier actors.json et va construire la
liste des acteurs dont le film d’intérêt movie['id'] se trouvera dans la
liste des films actor['films'].
|
Tip
|
Nous utilisons ici une liste compréhension Pyhton qui permet de
construire des listes de façon très concise et élégante.
|
4.5. Création du type, binding et schéma associé
Nous allons maintenant devoir déclarer le type actor
actor = ObjectType('Actor')Nous allons devoir attacher notre resolver à la liste des acteurs à
construire dans le type Movie du schéma. Pour cela nous utilisons comme
avant la méthode set_field mais cette fois pour l’objet movie que nous
avons construit. Le field à résoudre dans le schéma est actors et nous y
associons notre resolver r.resolve_actors_in_movie.
movie.set_field('actors', r.resolve_actors_in_movie)Enfin, à la création de notre schéma exécutable nous devons ajouter le type
actor.
schema = make_executable_schema(type_defs, movie, query, mutation, actor)4.6. Tests
Relançons notre service et envoyons à nouveau notre requête :
query{
movie_with_id(_id:"96798c08-d19b-4986-a05d-7da856efb697") {
title
rating
actors{
firstname
lastname
birthyear
}
}
}{
"data": {
"movie_with_id": {
"actors": [
{
"birthyear": 1974,
"firstname": "Leonardo",
"lastname": "DiCaprio"
},
{
"birthyear": 1964,
"firstname": "Monica",
"lastname": "Bellucci"
},
{
"birthyear": 1958,
"firstname": "Alain",
"lastname": "Chabat"
}
],
"rating": 7.4,
"title": "The Night Before"
}
}
}Ainsi, sans modification des points d’entrée existants, ni sans création d’un
nouveau point d’entrée les clients peuvent s’ils le souhaitent demander des
informations sur les acteurs pour le film d’intérêt. Cela illustre la grande
flexibilité offerte par GraphQL dans la gestion des interfaces.
Les utilisateurs qui utilisaient la requête du début
query{
movie_with_id(_id:"96798c08-d19b-4986-a05d-7da856efb697") {
title
rating
}
}ont toujours le même résultat et n’ont donc rien à modifier à leur code.
5. Pour terminer
Si l’on souhaite faire plusieurs requêtes ou plusieurs mutations, il faut les réunir dans le schéma sous cette forme :
type Query {
movie_with_id(_id: String!): Movie
actor_with_id(_id: String!): Actor
}